Powielona treść (duplicate content) w sklepie internetowym – skąd się bierze i jak sobie z nią radzić?
Pozycjonowanie sklepu internetowego
eKomercyjnie.pl
Autorem poniższego poradnika jest Sebastian Suma z agencji interaktywnej NetArch, która zajmuje się m.in. optymalizacją i pozycjonowaniem sklepów internetowych, a także kampaniami Google AdWords (pod marką Sempai.pl).
Zapewne każdy z właścicieli sklepów internetowych, którzy dbają o optymalizację SEO swojej platformy, spotkał się z problemem tzw. “duplicate content”. O ile nie jest to przypadłość, która może spowodować duże kłopoty, to wyeliminowanie jej z pewnością przyniesie korzyści w postaci lepszej indeksacji sklepu w wyszukiwarkach.
Dlatego jednym z ważniejszych elementów dobrego SEO dla sklepu internetowego jest wykrycie i wyelimonowanie kopii już zaindeksowanych podstron serwisu. Platformy e-commerce są w dużym stopniu narażone na pojawianie się tego typu błędów ze względu na swoją budowę: duża liczba produktów (landing pages), podstrony z wynikami wyszukiwania, stronicowanie listy produktów oraz pokusa na powielanie opisów produktów (zarówno wewnątrz swojego sklepu, jak i z serwisów zewnętrznych).
Problem „duplicate content” tworzy się z dwóch powodów: kiedy ta sama treść występuje na kilku podstronach i brakuje wskazania dla wyszukiwarek, która z nich jest główna/preferowana, oraz poprzez wykorzystywanie zapożyczonych opisów produktów (dostarczone przez producenta, skopiowane z innych stron www). Warto mieć również świadomość, że “duplicate content” w oczach Google nie oznacza dokładnej kopii podstrony już zaindeksowanej, a jest to podstrona, która niczym istotnym nie odróżnia się od strony już zaindeksowanej.
Jakie konsekwencje niesie ze sobą występowanie „duplicate content” w serwisach internetowych?
W praktyce nie występuje fizyczna kara dla serwisu www nakładana przez algorytmy wyszukiwarek (w postaci filtrów czy banów). Po prostu słabo zoptymalizowane strony z kopiami treści indeksowane są nisko w wynikach wyszukiwania. Google za pomocą swoich algorytmów mierzy jakość serwisów www, promując w SERP te dobrze zoptymalizowane, spychając na dalsze pozycje te o niskiej jakości, niedopracowane zgodnie z wytycznymi dla webmasterów. Nie jest tajemnicą teza „content is king”, co oznacza, że unikalność i jakość treści w serwisach mają wysoki priorytet przy ustalaniu wyników na stronach wyszukiwania.
Przyczyny występowania „duplicate content” w sklepach internetowych?
1. Kopie opisów produktów. Jedną z ważniejszych przyczyn błędu jest używanie opisów produktów dostarczanych przez producentów oraz kopiowanie opisów z innych sklepów internetowych. Niestety ten problem dotyczy dużej liczby sklepów. Brak unikalnych opisów na podstronach serwisu nie tylko może być powodem słabych wyników w wyszukiwarkach, może też mieć wpływ na słabą konwersję sprzedaży (w przypadku treści od producentów, które w większości nie są „skrojone” pod użytkowników Internetu).
Rozwiązanie tego problemu jest trywialne: zadbać o unikalne, ciekawe opisy wszystkich produków w sklepie. Natomiast jeśli nie jest to możliwe, warto próbować uzyskać unikalność podstrony poprzez umieszczenie na niej dużej ilości dodatkowych treści, poprzez:
dodanie własnych opini/testów produktów;
zapewnienie unikalnych opinii dodawanych przez Klientów sklepu;
udostępnienie mechanizmu komentarzy do produktu/zakupów;
umieszczenie listy produktów komplementarnych lub podobnych, np. z tej samej kategorii.
2. Duplicate content generowane przez skrypt sklepu internetowego.
a) Sortowanie produktów w sklepie. Mechanizm sortowania produktów powoduje tworzenie wielu podstron serwisu z tą samą treścią, gdzie jedyną różnicą jest kolejność prezentowania treści na stronie. Strony te oprócz identycznych treści posiadają również identyczne meta tagi: Title i Description.
b) Paginacja listy produktów. W większości przypadków problem ze stronicowaniem listy produktów sprowadza się do powtarzania tych samych meta tagów (Title, Description) na wszystkich podstronach listy produktów. Ponadto, brak odpowiedniego wyakcentowania głównej (pierwszej) strony danej kategorii produktów wprowadza niejednoznaczność co do adresów URL, które wyszukiwarki powinny indeksować wysoko dla zapytań z nią związanych. W efekcie „moc” linkowania wewnętrznego rozmywa się po wielu podobnych podstronach, zamiast optymalnie koncentrować na jednej, umożliwiając jej wysokie pozycjonowanie.
c) Duplikowanie treści pod wieloma adresami:
z www czy bez www? Brak wskazania głównego adresu sklepu;
wiele „stron głównych” sklepu, np. www.nazwasklepu.pl, www.nazwasklepu.pl/index.php, www.nazwasklepu.pl/pl/;
indeksacja tego samego widoku (np. karty produktu) z różnym adresem URL: www.sklep.pl/kategoriaA/produkt1.html vs. www.sklep.pl/kategoriaB/produkt1.html
d) Strony „do druku”. W wielu sklepach internetowych jest przygotowana specjalna wersja strony pod wydruk, która posiada swój unikalny adres URL. Taka strona jest pod względem treści dokładną kopią karty produktu, w okrojonej szacie graficznej. Problem pojawia się w momencie, kiedy wyszukiwarka wyżej zaindeksuje wersję „do druku”, pozostawiając nisko w wynikach wyszukiwania „prawdziwą” podstronę.
Jak radzić sobie z „duplicate content”?
Jednym ze sposobów jest wskazywanie algorytmom wyszukiwarek kanonicznej, czyli preferowanej wersji podstrony przy pomocy tagu [rel=canonical]. Ten TAG przekazuje siłę wszystkich linków dla jednego adresu URL, dzięki czemu zyskuje on lepszą wartość podczas indeksacji. Dodatkową korzyścią jest to, że to właściciel sklepu, a nie algorytm wyszukiwarki wskazuje, która podstrona ma być wskazywana użytkownikom/klientom w wyszukiwarkach.
Dla przykładu, zamiast posiadać kilka słabo zaindeksowanych wersji podstrony: http://www.nazwasklepu.pl/kategoria_produktow#sort=name http://www.nazwasklepu.pl/kategoria_produktow#sort=price http://www.nazwasklepu.pl/kategoria_produktow#sort=date http://www.nazwasklepu.pl/kategoria_produktow#sort=purchases
można mieć wysoko zaindeksowaną główną stronę dla kategorii: http://www.nazwasklepu.pl/kategoria_produktow
poprzez umieszczenie na stronach sortowania odpowiedniego wpisu w sekcji HEAD w postaci:
Na problem „duplicate content” powodowany mechanizmem paginacji (stronicowania) listy produktów, lekiem jest stosowanie tagów [rel=next] oraz [rel=prev], które pozwalają wskazać robotom wyszukiwarek, które strony zawierają paginacje i jaka jest ich pozycja w strukturze stronicowania.
W przypadku występowania tej samej podstrony sklepu pod różnymi adresami URL, najlepszym sposobem jest skorzystanie z mechanizmu przekierowań 301. Ten zabieg również powoduje przekazanie całej siły linków na jeden docelowy adres URL. Natomiast w celu wyeliminowania indeksacji wybranych stron (np. Stron „do druku” czy wyników sortowania), warto skorzystać z umieszczenia na tych podstronach meta tagu [CONTENT=”NOINDEX, NOFOLLOW”] lub stworzenia odpowiedniego wpisu w pliku robots.txt, umieszczonego na tym samym serwerze, co skrypt sklepu internetowego.
Jak badać i eliminować zjawisko duplicate content z pomocą Narzędzi Google dla Webmasterów?
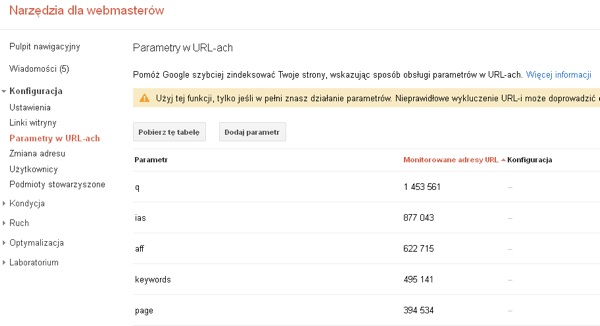
GWT -> Konfiguracja -> Parametry w URL-ach
Jedną z najczęstszych przyczyn generowania zjawiska „duplicate content” dla witryny w indeksach wyszukiwarek jest zbędne indeksowanie wielokrotnie tego samego widoku z różnymi parametrami w adresie URL. Częściowo da się to eliminować programistycznie, ale nie zawsze. Wówczas z pomocą przychodzi panel GWT, gdzie można wskazać wszelkie parametry (np. występujące przy sortowaniu produktów w sklepie), których wyszukiwarka ma nie uwzględniać w indeksacji. Parametry takie bywają automatycznie diagnozowane przez Googlebota, natomiast warto wymusić na nim pożądaną decyzję, w przypadkach ewidentnych, jak również można dodawać własne parametry, których Googlebot (jeszcze) nie wykrył, a dla których chcemy uniknąć indeksacji.
GWT -> Optymalizacja -> Udoskonalenia HTML -> Podwójne tagi tytułowe
Raport ten z założenia służy diagnozowaniu miejsc w witrynie, dla których występują zdublowane tagi tytułowe (a więc w szczególności meta tagn